

Разработка веб-сервиса для создания цифрового двойника человека
AI-REPLICA (также известный как Afterlife.ai / Timeless.ai) — это инновационный веб-сервис, предназначенный для создания высокореалистичного цифрового двойника (AI-Replica) человека.
В основе продукта лежит AI-чат, который сочетает в себе глубокую профильную персонализацию с продвинутой технологией генерации с дополненной выборкой (RAG, Retrieval-Augmented Generation).
Проект был инициирован частным лицом (Австралии) через нашего партнера. Для нашей команды это был первый опыт сотрудничества с данным клиентом, что потребовало выстраивания всех процессов с нуля, начиная с глубокого погружения в очень личную и деликатную концепцию продукта.

Задача
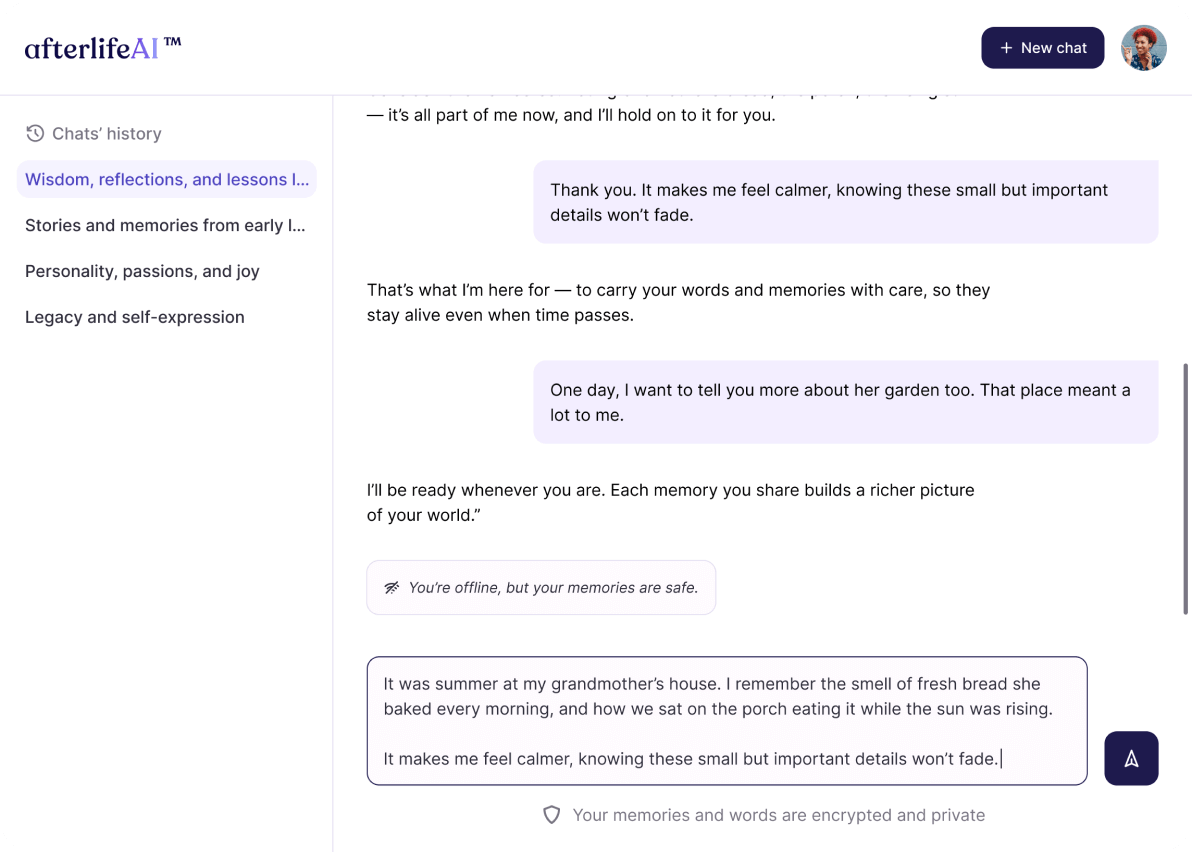
Основная задача, поставленная клиентом, была амбициозной и выходила за рамки стандартной разработки чат-ботов. Требовалось создать «цифровой слепок личности» — реплику конкретного человека в виде чат-бота, который бы не просто отвечал на вопросы, а полностью повторял манеру общения, оперировал фактами из биографии и демонстрировал характерные черты личности этого человека.
Конечная цель системы, как ее видел клиент, — предоставить возможность родственникам и близким продолжать «общение» с человеком после его ухода, сохранив его цифровую память.
Если перевести эту концепцию на язык технических и бизнес-целей, проект должен был решить следующие ключевые задачи (Objectives):
- Обеспечить глубоко персонализированные AI-диалоги: Добиться того, чтобы ответы ИИ были не просто общими, а последовательными, естественными и основанными на уникальном профиле личности.
- Реализовать бесшовный онбординг (Wizard): Разработать интуитивно понятный многошаговый опросник (wizard) для сбора специфических данных о пользователе. Эти данные — от любимых книг и фактов биографии до политических взглядов и стиля общения — должны были стать основой для «личности» ИИ.
- Создать надежный механизм извлечения контекста (RAG): Построить архитектуру, при которой ИИ в реальном времени динамически извлекает нужные факты из созданного профиля во время диалога, чтобы генерировать релевантные ответы.
Изначально целевая аудитория виделась достаточно узкой: пожилые люди и пациенты с серьезными заболеваниями, которые хотели бы оставить после себя такой цифровой след. Однако в процессе аналитики стало очевидно, что потенциальная аудитория гораздо шире — это любой пользователь (End User), который по тем или иным причинам хочет создать свой персонализированный цифровой двойник для общения.

Решение
Для реализации столь сложной задачи мы предложили современную и модульную архитектуру.
Ключевым элементом решения стал сложный RAG-поток (Retrieval-Augmented Generation). Вместо того чтобы просто отправлять запрос пользователя в LLM (как это делают простые чат-боты), наша система выполняет многоступенчатый процесс:
- Анализирует запрос пользователя.
- Мгновенно выполняет семантический поиск по векторной базе данных (Qdrant), где хранятся все факты и черты личности пользователя.
- Находит наиболее релевантные "кусочки" информации (например, "факт о детстве", "мнение о музыке").
- "Дополняет" (Augmented) первоначальный запрос пользователя этой информацией.
- Отправляет этот обогащенный, высококонтекстный промпт в LLM (OpenAI) для генерации (Generation) ответа.
Этот подход гарантирует, что ИИ "помнит", кто он, и отвечает в соответствии со своей "личностью".
Процесс разработки
Проект был спланирован как интенсивная разработка MVP (Minimum Viable Product) с очень сжатыми сроками.
- Календарный срок: 1 месяц (разбит на 4 спринта по 1 неделе).
- Оценка трудозатрат (MVP): от 352 до 473 общих часов.
Процесс был выстроен максимально параллельно, чтобы уложиться в дедлайны:
- Аналитика, Дизайн и Прототипирование (Параллельно):
- Аналитика: Бизнес-аналитик прорабатывал требования к Website и Backend, описывая логику Wizard, API и RAG-потоков.
- Дизайн: Дизайнер в Figma создавал интерфейс чата, экраны многошагового опросника и "сценарий первого контакта" пользователя с системой.
- Прототипирование: На этом проекте мы применили нестандартный подход. Поскольку оценка результата ("похоже на человека или нет") носит крайне субъективный характер, мы сначала создали быстрый прототип на low-code платформе n8n. Это позволило нам быстро и с минимальными затратами протестировать саму концепцию ИИ-агентов, поэкспериментировать с логикой и сконцентрироваться на достижении наилучшего качества ответов ИИ, прежде чем писать сложный production-код.
- Разработка (Основной этап):
- Frontend (ReactJS): Разработка UI чата и опросника.
- Backend API (Ktor): Разработка API для аутентификации, управления профилями (Wizard) и обработки сообщений чата.
- Backend AI (Ktor/Koog/Qdrant): Самая сложная часть. Интеграция с OpenAI, реализация RAG-потоков, настройка PII-фильтра (для защиты личных данных) и конфигурация всего стека баз данных (Postgres, Redis, Qdrant).
- QA и PM (Сквозные процессы): Тестирование и управление проектом велись на протяжении всех спринтов.
Состав команды: Над проектом работала компактная и высокоэффективная кросс-функциональная команда:
- 1 Project Manager
- 1 Analyst
- 1 Designer
- 2 Backend-разработчика
- 1 Frontend-разработчик
- 1 QA-специалист
Что было самым сложным
В ходе разработки мы столкнулись с тремя основными вызовами, которые требовали нетривиальных инженерных решений.
- Сложность Персонализации (RAG-Flow): Это был главный вызов. Нужно было не просто "подключить" ChatGPT. Требовалось обеспечить, чтобы ИИ-двойник давал последовательные и персонализированные ответы, основываясь на десятках и сотнях фактов из профиля. Как сделать так, чтобы ИИ "вспомнил" нужный факт в нужный момент? Самой сложной задачей стала тонкая настройка системного промпта и логики подтягивания дополнительного контекста (фактов) из векторной базы данных Qdrant.
- Конфиденциальность Данных (PII): Профиль пользователя по своей сути должен был содержать огромное количество персонально идентифицируемой информации (PII) — имена, даты, личные истории, мнения. При этом архитектура подразумевала использование внешнего API (OpenAI). Возник критический конфликт: как использовать эти данные для персонализации, не передавая их во внешний API в явном виде? Обеспечение конфиденциальности PII стало абсолютным приоритетом.
- Производительность (NFR): Эффект "живого" общения пропадает, если чат-бот "думает" над ответом 10-15 секунд. У нас было строгое нефункциональное требование (NFR): среднее время ответа чата не должно превышать 5 секунд. Это очень агрессивная цель, учитывая сложность нашего RAG-потока: за эти 5 секунд система должна была получить сообщение, обратиться к Redis за историей, обратиться к Qdrant за фактами, сформировать сложный промпт, отправить его в OpenAI, получить ответ и вернуть пользователю.
Как мы решили эту задачу
Для каждого из трех вызовов наша команда разработала и реализовала конкретное техническое решение.
- Решение для RAG (Персонализация): Для достижения высокого качества ответов мы реализовали динамическую логику на бэкенде (Ktor + Koog).
- История: Сначала мы думали просто передавать в OpenAI весь профиль пользователя, но быстро поняли, что это неэффективно (ограничение токенов) и нерелевантно (ИИ "тонул" в лишней информации).
- Решение: Мы реализовали динамический поиск "Top-K". Когда пользователь отправлял сообщение, бэкенд сперва делал семантический запрос в Qdrant и находил 4–6 наиболее релевантных фактов (чанков) из профиля.
- Далее эти 4-6 фактов форматировались в специальный блок контекста и динамически "вклеивались" в итоговый промпт для OpenAI.
- Параллельно мы вели методичный промпт-инжиниринг, оттачивая главный системный промпт, чтобы научить ИИ правильно интерпретировать и использовать этот дополнительный контекст
- Решение для PII (Конфиденциальность): Для защиты PII мы внедрили механизм PII-фильтра и токенизации личных данных.
- История: Простое шифрование не подходило, так как OpenAI должен был понимать смысл данных для генерации векторов (embeddings).
- Решение: Мы разработали PII-фильтр на бэкенде. На этапе подготовки данных для векторной базы (перед отправкой в OpenAI Embeddings API), этот фильтр находил и заменял всю личную информацию на специальные токены. Например, "Мою собаку зовут [DOG_NAME_1]" или "Я живу в [USER_CITY_1]".
- Таким образом, внешний API OpenAI никогда не видел реальных имен, адресов или кличек. Он оперировал только безличными токенами, что полностью снимало риски утечки PII. При этом в нашей внутренней PostgreSQL базе хранилось сопоставление токенов и реальных данных.
- Решение для Производительности (NFR): Чтобы уложиться в 5 секунд, нам нужно было оптимизировать каждый шаг. Главным "пожирателем" времени и токенов является передача всей истории чата.
- История: "Наивный" подход — отправлять в OpenAI всю историю переписки с каждым новым сообщением. Это быстро приводило к превышению лимита токенов и замедляло ответ.
- Решение: Мы использовали Redis для управления сессиями и хранения недавней истории чата (memory). Вместо всей истории мы отправляли только "скользящее окно" последних сообщений. Это позволило поддерживать непрерывность разговора (ИИ помнил, о чем шла речь 2 минуты назад), но при этом кардинально сокращало количество передаваемых токенов и оптимизировало нагрузку на API. Это решение напрямую ускорило время ответа и снизило стоимость каждого запроса.
Технологический стек
Frontend
 ReactJS
ReactJS Flowbite (Tailwind CSS) UI-kit
Flowbite (Tailwind CSS) UI-kitBackend
 Ktor (Kotlin)
Ktor (Kotlin) Koog by JetBrains
Koog by JetBrainsБазы данных
 PostgreSQL
PostgreSQL Redis
Redis Qdrant
QdrantAI Сервисы
 OpenAI API
OpenAI APIПрочее
 Stripe для интеграции платежей
Stripe для интеграции платежей Digital Ocean (хостинг)
Digital Ocean (хостинг) n8n
n8nРезультат
Проект был запланирован как быстрый MVP сроком в один месяц. К сожалению, по причинам, не зависящим от команды разработки, проект не был завершен и внедрен в полном объеме.
Мы успели провести глубокую аналитику, создать полный дизайн продукта, разработать и протестировать архитектуру и ключевые сложные механики, включая RAG-поток и PII-фильтр.
Мы не располагаем информацией о дальнейшей судьбе проекта. Команда передала заказчику все наработки, которые успела сделать:
- Полную документацию и аналитику.
- Готовые дизайн-макеты в Figma.
- Папку проекта с документацией.
- Разработанную кодовую базу с реализованной архитектурой
Несмотря на то, что продукт не дошел до релиза, для нашей команды этот кейс стал ценным опытом в разработке сложных, высокопроизводительных и безопасных AI-систем с использованием RAG-архитектуры. Мы успешно решили нетривиальные задачи по защите PII и оптимизации производительности в работе с LLM.

